Robots.txt
<< Crawl Rate
Page Speed >>
<< Crawl Rate
Page Speed >>
Robots.txt
Robots.txt file tells search engine bots what parts or sections of the website to not crawl. Major search engines like Google, Yahoo, Bing obeys Robots.txt requests.
How does Robots.txt work?
Any search engine has two important functions:
- Crawling the web to find content;
- Indexing the content in its database to serve to the users later
To crawl sites, search engines follow links to get from one site to another. This is how they end up following billions of links and sites. This behavior is also known as “spidering.”
After arriving at a link and before spidering the site, these spiders look for a robots.txt file. In fact, the first URL they look for is this:
example.com/robots.txt
Now if it finds a robots.txt file (that actually contains directives for the spiders on what parts/sections on site they should not crawl). In case, there’s no robots.txt file – they’ll just follow the other information available on the site.
Why Robots.txt is important?
Most of the websites don’t need a robots.txt file. Google automatically crawls important pages and is smart enough to leave unimportant pages or duplicate pages.
So majorly there could be three scenarios when you need a robots.txt file on your site:
Private Pages
When you have a private page on your website that you don’t want to make available for the general public. In other words, the page you don’t want to be indexed.
For example, You have a login page on your site. These kinds of pages are also important. But it doesn’t make sense that random people landing on that page. Hence you can block this page with a robots.txt file.
Maximize Crawl Budget
When your site is suffering from a low crawl budget. You want to make sure that at least important pages on the site do get crawled first. You can do so by blocking unimportant pages on your site using robots.txt. That way, Google can spend more time crawling the pages that matter the most.
Prevent Indexing of Multimedia Files
Meta directives can also work in place of Robots.txt to block certain pages from getting crawled. But Meta directives don’t work well when you have to block multimedia content like images and PDFs.
This is when you have to make use of robots.txt
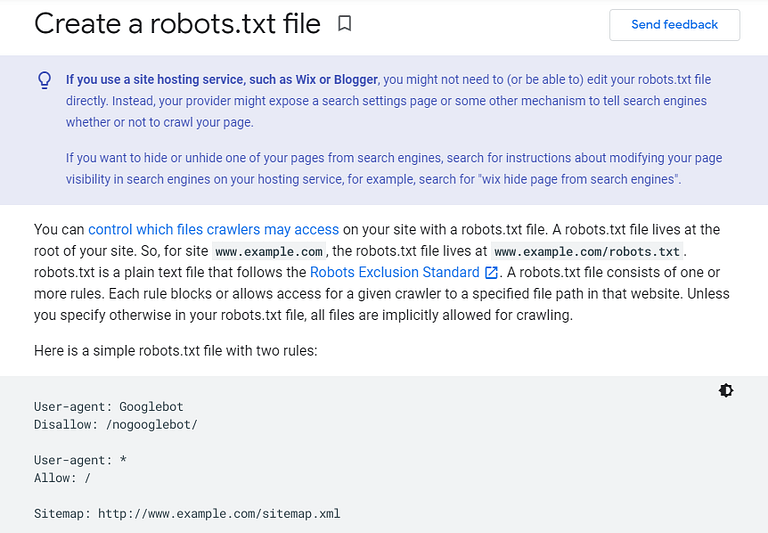
How to create Robots.txt

Basic format
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
User-agent is the specific bot you’re talking about.
And everything that you mention after “disallow” are the pages/sections on your site that you want to block.
Robots.txt is a text file. So you can actually create it on a Windows notepad.
Let’s understand from an example:
User-agent: Googlebot
Disallow: /example-subfolder/
This syntax tells Google’s crawler (user-agent name Google crawler/spider/bot) not to crawl any pages that contain the URL starts with www.example.com/example-subfolder/.
Another example:
User-agent: *
Disallow: /image
This syntax tells any and all the crawlers (user-agent name *) not to crawl your images folder.
There are many other ways you can create the directives for the crawlers.
Check out the guide from Google to learn and create more rules for the crawlers.
Test Robots.txt file
Creating and uploading robots.txt file to your site can be very critical if you do it wrong.
One small mistake and it might get your whole site deindexed.
So make sure you test your robots.txt file before uploading it to your site.
Here is a free testing tool from Google.

As you can see, we have blocked our WordPress-generated tag pages to avoid duplicate content.
We also have blocked the Wp-admin page.
And allowed ajax file since Google wants to see how your site is constructed including CSS, JS, and Ajax files.
Also allowed sitemap since it contains a list of all of the web pages on your site. It’s a good practice to serve the sitemap to the crawlers right away in the first interaction itself.
How to Upload Robots.txt on your site
Once you have the robots.txt file tested and ready to be uploaded – make it easy to find.
In order to be found, a robots.txt file must be placed in the root folder of your site.
As I told you before, the very first URL a crawler will look for on your website is: https://example.com/robots.txt
So it’s the best practice to place your robots.txt file at this URL.
Robots.txt must-knows
- Not all crawlers may follow your robots.txt directives. The most common ones are malware robots or email address scrapers.
- The robots.txt file is publicly available. You can check it for any website. To check just add robots.txt at the end of the top URL. For example, to check it for adschoolmaster.com – search for – https://adschoolmaster.com/robots.txt
- In the case of a subdomain, create a separate robots.txt file. For example, blog.example.com and example.com should have their own robots.txt files. Like these: blog.example.com/robots.txt and example.com/robots.txt
Robots.txt vs Meta Directives
Meta Directives can also be used to block pages at the page-level with “noindex” tag.
However, robots.txt provides you an edge in a few scenarios:
Scenario 1. The noindex tag is tricky to implement on multimedia resources, like images, videos, and PDFs.
Scenario 2: In case, if you have hundreds and thousands of pages to block, can be a tedious task with noindex. Instead, you can use robots.txt to block the entire section on your site.
Scenario 3: Robots.txt is always a better choice if your site is struggling with a crawl budget. Because Google crawlers can still land on a page with a noindex tag on it.
Previous
<< Crawl Rate
Next
Page Speed >>